1.本章学习心得、体会
学习方法论:输入--输出---纠正
坚持 坚持 再坚持
2.学习到的知识点总结。
学习内容:
Python 3最重要的新特性大概是对文本和二进制数据做了更为清晰地区分。文本总是Unicode,由str类型表示,二进制数据由bytes类型表示。Python 3不会以任意隐式的方式混用str和butes,正因为此,python 3不能拼接字符串和字符包,也无法在字节包里搜索字符串,不能讲字符串传入参数为字节包的函数。
str 转为 bytes – encode
>>> "fgf".encode('utf-8')
b'fgf'
>>> "活着".encode('utf-8') # utf-8编码转为二进制
b'\xe6\xb4\xbb\xe7\x9d\x80'
# python 2.x 不指定编码,则使用系统编码
# python 3.x 不指定编码,则使用utf-8
bytes 转为 str – decode
>>> b'\xe6\xb4\xbb\xe7\x9d\x80'.decode('utf-8')
'活着' # 二进制转为utf-8编码
python 数据传输,都是以二进制数据传。
二进制和十六进制的转化
十六进制:二进制每4位表示16进制的一位。对应关系如图
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
| 0000 | 0001 | 0010 | 0011 | 0100 | 0101 | 0110 | 0111 | 1000 | 1001 | 1010 | 1011 | 1100 | 1101 | 1110 | 1111 |
二进制转换成十六进制的方法是,取四合一法,即从二进制的小数点为分界点,向左(或向右)每四位取成一位
1011 1001 1011 1001 # 二进制 v v v v V B 9 B 9 # 十六进制
注意16进制的表示法,用字母H后缀表示,比如BH就表示16进制数11;也可以用0X前缀表示
在向左(或向右)取四位时,取到最高位(最低位)如果无法凑足四位,就可以在小数点的最左边(或最右边)补0,进行换算
将十六进制转为二进制,一分四,即一个十六进制数分成四个二进制数,用四位二进制按权相加,最后得到二进制,小数点依旧就可以
B F 4 . B 5 # 十六进制 v v v v v V 1011 1111 0100.1011 0101 # 二进制
列表
命名规则“[]”
name = ["A","B","C","D","E"]
取值
print(name[0], name[1])
print(name[1:3]) # 切片,顾头不顾尾
name[-1] # 取最后一个
# name[-1:-3] # 从左往右,这样取不到值
name[-3:-1] # 取倒数第三到最后一个
name[-2:] # 取最后两个
添加:
names.append("") # 追加
names.insert(1,"") # 插入哪写哪
修改:
names[2] = "" # 修改
删除:
names.remove("fgf") # 删第一个从左往右
del names[1]
names.pop(1) # 坐标为空则删最后一个
取下标:
names.index("fgf") # 取下标
统计:
names.count("fgf") # 统计
排序: # 按ascii码排序,符号、数字、大写小写
names.sort() # 排序
反转:
names.reverse() # 反转
清除列表:
names.clear() # 清空
扩充:
names2 = [1,2,3,4]
names.extend(name2) # 扩充
del names2 # 删掉变量
遍历:
for i in names: #遍历列表
print i
步长:
range(1,10,2)
names[0:-1:2] <--> names(::2)
元组:
元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能再修改,所以又叫只读列表
语法
names = ("alex","jack","eric")
它只有2个方法,一个是count,一个是index,完毕。
字典:
字典一种key - value 的数据类型
语法:
info = {
'stu1101': "台湾",
'stu1102': "钓鱼岛",
'stu1103': "南海", 字典的特性:
dict是无序的
key必须是唯一的,so 天生去重
增加或修改
info["stu"] = "fgf" # 存在为修改,不存在为添加
删除
del info["stu"] # 删除
info.pop("stu")
查找
"fgf" in info # 标准用法
info.get("stu") # 获取
info["stu"] # 如果不存在,就报错,get不会,不存在返回None
-----------------------------------------------------------------------------
取Values
info.values()
取keys
info.keys()
setdefault
info.setdefault("stu1102", "小日本") # key有则不变,没有就创建
update
b = {1:2,3:4, "stu1102":"钓鱼岛是中国的"}
info.update(b) # 类似列表的extend
info.items()
循环字典
# 方法1
for index,item in enumerate(info):
print(index,item)
# 方法2
for key in info: # 效果一样,比下面高效
print(key,info[key])
# 方法3
for k,v in info.items(): #会先把dict转成list,数据里大时莫用
print(k,v)
}
深copy和浅copy
1、数字和字符串
上篇提了:对于数字数字和字符串一旦创建便不能被修改,假如对于字符串进行替代操作,只会在内存中重新生产一个字符串,而对于原字符串,并没有改变。
2、字典、列表等数据结构
alphabet = ["A","B","C",["L","M","N"]]
alphabet2 = alphabet.copy()
alphabet3 = alphabet
import copy
alphabet4 = copy.copy(alphabet)
alphabet5 = copy.deepcopy(alphabet)
请想一下:如果对alphabet的值做更改,其他四个变量的值会不会变化呢?
alphabet[2] = 2
alphabet[3][1] = 7
>>> alphabet
['A', 'B', 2, ['L', 7, 'N']]
下面分别看一下其他四个变量的值:
>>> alphabet # 更改后的值
['A', 'B', 2, ['L', 7, 'N']]
>>> alphabet2 # list.copy()
['A', 'B', 'C', ['L', 7, 'N']]
>>> alphabet3 # "="赋值
['A', 'B', 2, ['L', 7, 'N']]
>>> alphabet4 # copy.copy()
['A', 'B', 'C'['L', 7, 'N']]
>>> alphabet5 # copy.deepcopy()
['A', 'B', 'C'['L', 'M', 'N']]
总结一下
1、直接“=”赋值,都指向同一个内存地址,alphabet变,alphabet3也变。和简单的数字、字符串不一样
2、list.copy()和copy模块的copy.copy()一样,都是浅copy,只copy了第一层,下面的层只是copy内存地址,源变量深层被更改,则更改。
3、完全克隆,不只拷贝内存地址,则要深copy,使用copy模块的copy.deepcopy()
字典的fromkeys用法也是一样。如下:
>>> deposit = dict.fromkeys(['husband','wife'],{"总存款:":"100w"})
>>> deposit
{'husband': '100w存款', 'wife': '100w存款'}
>>> deposit['husband']["总存款:"] = "80w"
>>> deposit
{'husband': {'总存款:': '80w'}, 'wife': {'总存款:': '80w'}}
# 改其中一个的值,其他的值就都改了。第一层不变,深层就都变了,
集合:
集合是一个无序的,不重复的数据组合,它的主要作用如下:
- 去重,把一个列表变成集合,就自动去重了
- 关系测试,测试两组数据之前的交集、差集、并集等关系
1、常用操作
去重
list_1 = [1,1,2,3,4,5,6,6,7,7,8,8,9,9,3]
set_1 = set(list_1)
>>> set_1
{1, 2, 3, 4, 5, 6, 7, 8, 9}
# 集合用{}表示
交集
set_2 ={0,2,3,4}
set_1.intersection(set_2)
并集:
set_1.union(set_2)
差集:
set_1.difference(set_2)
# in set_1 but not in set_2
子集:
set_1.issubset(set_2)
父集:
set_1.issuperset(set_2)
对称差集:(并集去除交集,即并集和交集的差集)
set_1.symmetric_difference(set_2)
(set_1 | set_2) - (set_1 & set_2)
判断有没有交集,无交集,返回True
set_1.isdisjoint(set_2)
2、符号操作
& : 交集 intersection | :并集 union - :差集 difference s <= t :子集 issubset s >= t :父集 issuperset ^ :对称差集 symmetric_difference
3、集合增删改查
添加: set_1.add(99) 批量添加 set_1.update([1,2,3,4]) 删除: set_1.remove('h') # 没有则报错 set_1.discard(99) # 在则删除,不在就不操作。无返回信息 随机删: set_1.pop() 长度: len(set_1) 是否属于判断 s in set_1 # (判断成员在不在都是这么写,字典中判断key) 返回 set “s”的一个浅复制 s.copy()
字符编码与转码
1、Python编码详解
为什么我们要加“#-*- coding:utf-8 -*-”这一行?意思是置顶编码类型为utf-8编码!
为什么我们能看到这些文字、数字、图片、字符、等等信息呢?大家都知道计算机本身只能识别 0 1 的组合,他们是怎么展示这些内容的呢?我们怎么和计算机去沟通呢?
那怎么办?如何让计算机理解我们的语言,并且我们能理解计算机的语言呢?
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
在存储英文的时候我们至少需要1个字节(一个字母),就是8位(bit),看下ASCII表中1个字节就可以表示所有的英文所需要的字符,是不非常高效!
为什么呢?早期的计算机的空间是非常宝贵的!
那你会发现1个字节8位,他能存储的最大数据是2的8次方-1 = 255,一个字节最多能表示255个字符 那西方国家他们使用了127个字符,那么剩下字符是做什么的呢?就是用来做扩展的,西方人考虑到还有其他国家。所以留下了扩展位。
ASCII到了其他国家,完全不够用,于是就在原有的扩展位中,扩展出自己的gbk、gb2312、gb2318等字符编码。
他是怎么扩展的呢?比如说在ASCII码中的128这个位置,这个位置又指定一张单独表
于是每个国家都有自己的字符编码,也产生了1、没有字符集: 2、字符集冲突
为了统一起来,Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码
它为每种语言中的每个字符设定了统一并且唯一的二进制编码,
规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536, 注:此处说的的是最少2个字节,可能更多。
这里还有个问题:使用的字节增加了,那么造成的直接影响就是使用的空间就直接翻倍了!
为了解决个问题就出现了:UTF-8编码
UTF-8编码:是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存…
OK 上面了解了:
1、什么ASCII编码
2、什么Unicode编码
3、什么UTF-8编码
回顾下乱码的出现原因:1、没有字符集 2、字符集冲突
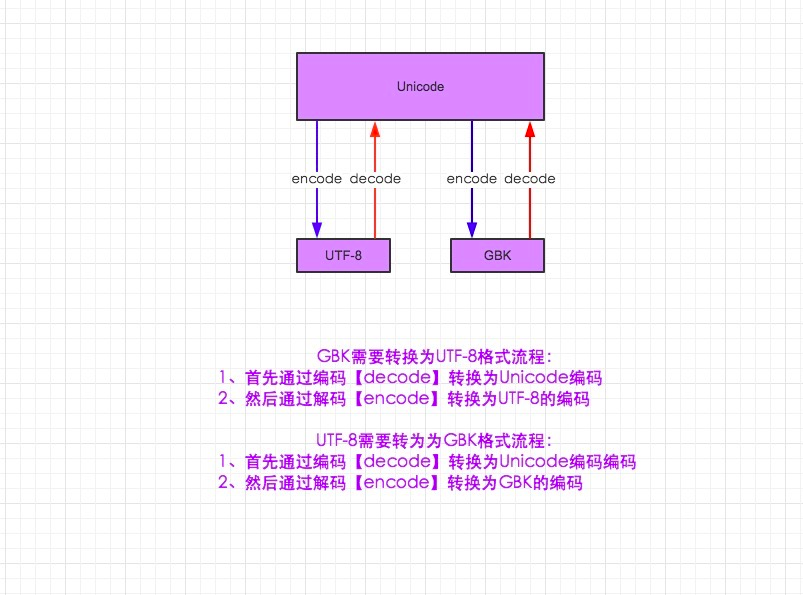
2、Python编码转换
python3中,默认就是unicode编码
name = '中国' # 转为UTF-8编码 print(name.encode('UTF-8')) # 转为GBK编码 print(name.encode('GBK')) # 转为ASCII编码(报错为什么?因为ASCII码表中没有中文字符集~~) print(name.encode('ASCII'))
Python2.X中的编码转换
python2.X中默认是ASCII编码,你在文件中指定编码为UTF-8,但是UTF-8如果你想转GBK的话是不能直接转的,的需要Unicode做一个转接站点
#-*- coding:utf-8 -*- import chardet tim = '你好' print chardet.detect(tim) # 先解码为Unicode编码,然后在从Unicode编码为GBK new_tim = tim.decode('UTF-8').encode('GBK') print chardet.detect(new_tim) # 结果 ''' {'confidence': 0.7525, 'encoding': 'utf-8'} {'confidence': 0.99, 'encoding': 'GB2312'} '''声明只是文件的编码,python 3 的变量都是Unicode编码
作业:
作业题目: 三级菜单
作业需求:
数据结构:
menu = {
'北京':{
'海淀':{
'五道口':{
'soho':{},
'网易':{},
'google':{}
},
'中关村':{
'爱奇艺':{},
'汽车之家':{},
'youku':{},
},
'上地':{
'百度':{},
},
},
'昌平':{
'沙河':{
'老男孩':{},
'北航':{},
},
'天通苑':{},
'回龙观':{},
},
'朝阳':{},
'东城':{},
},
'上海':{
'闵行':{
"人民广场":{
'炸鸡店':{}
}
},
'闸北':{
'火车战':{
'携程':{}
}
},
'浦东':{},
},
'山东':{},
}
需求:
可依次选择进入各子菜单
可从任意一层往回退到上一层
可从任意一层退出程序
所需新知识点:列表、字典
#三级菜单
menu = {
'北京':{
'海淀':{
'五道口':{
'soho':{},
'网易':{},
'google':{}
},
'中关村':{
'爱奇艺':{},
'汽车之家':{},
'youku':{},
},
'上地':{
'百度':{},
},
},
'昌平':{
'沙河':{
'老男孩':{},
'北航':{},
},
'天通苑':{},
'回龙观':{},
},
'朝阳':{},
'东城':{},
},
'上海':{
'闵行':{
"人民广场":{
'炸鸡店':{}
}
},
'闸北':{
'火车战':{
'携程':{}
}
},
'浦东':{},
},
'山东':{},
}
current_layer = menu
last_layer = []
while True:
for m in current_layer:
print(m)
choice = input('>:').strip()
if not choice:continue
if choice in current_layer:
last_layer.append(current_layer)
current_layer = current_layer[choice]
elif choice == 'b':
if len(last_layer) !=0:
current_layer = last_layer.pop()
else:
print("已经是顶层。")
elif choice == 'q':
exit ("bye.")
else:
print ("您输入的城市不正确,请重新输入,返回上级请输1,退出请输q")
作业题目: 购物车程序
作业需求:
数据结构: goods = [ {"name": "电脑", "price": 1999}, {"name": "鼠标", "price": 10}, {"name": "游艇", "price": 20}, {"name": "美女", "price": 998}, ...... ] 功能要求: 基础要求: 1、启动程序后,输入用户名密码后,让用户输入工资,然后打印商品列表 2、允许用户根据商品编号购买商品 3、用户选择商品后,检测余额是否够,够就直接扣款,不够就提醒 4、可随时退出,退出时,打印已购买商品和余额 5、在用户使用过程中, 关键输出,如余额,商品已加入购物车等消息,需高亮显示
#购物车程序
goods = [
{"name": "电脑", "price": 1999},
{"name": "鼠标", "price": 10},
{"name": "游艇", "price": 20},
{"name": "美女", "price": 998},
]
shopping_car =[]
exit_flag=False
total_cost=0
username="1234"
user_password="1234"
while not exit_flag:
user = input ("请输入用户名:").strip()#用户名
password = input ("请输入密码:").strip()#密码
if username == user and password == user_password:
print("欢迎",username,"来Python开发入门14天集训营")
break
else:
print("输入的username or password 错误。")
continue
while not exit_flag:
salary = input ("请输入您的工资:").strip () # 输入金额
if salary.isdigit (): # 判断输入的salary是不是数字
salary = int (salary)
else:
print ("由于您的输入的工资不合法,请再次输入金额") # 输入金额不合法
continue
while not exit_flag:
print ("商品列表".center (30, "-"))
for index, g in enumerate (goods):
print ("%s. %s %s" % (index, g.get ("name"), g.get ("price")))
choice=input("\033[31;1m请输入要选择的商品列表前的数字或退出(q/Q):\033[0m")
if choice.isdigit():# 判断输入的choice是不是一个数字
choice=int(choice)
if choice >= 0 and choice < len(goods):# 选择商品编号必须小于商品列表的数量
goods_item = goods [choice] # 获取商品
if goods[choice].get("price") <= salary :# 拿现有金额跟商品对比,是否买得起
shopping_car.append (goods[choice]) # 把选着的商品加入购物车
salary -= goods_item.get("price")# 扣完商品的价格
print ("已购买的商品:\033[31;1m{shop},当前的用户余额:\033[31;1m{balance}元\033[0m".format(shop = shopping_car,balance = salary))
else:
print ("余额不足,不能购买此商品,只有:\033[31;1m{balance}元\033[0m".format(balance=salary))
else:
print ("\033[31;1m输入的编号超出商品列表内容,请重新输入\033[0m")
#break
elif choice == "q" or choice == "Q":#退出
if len(shopping_car) > 0:
print ("\033[31;1m购买以下商品\033[0m".center(30, "*"))
for index, g in enumerate (shopping_car):
print ("\033[31;1m%s. %s %s\033[0m" % (index,g.get("name"),g.get("price")))
total_cost += g.get("price")
print ("您的商品总价是:\033[31;1m{balance}\033[0m 元".format(balance=total_cost))
print ("您当前余额是:\033[31;1m{balance}\033[0m 元".format(balance=salary))
exit_flag = True
else:
print ("您没有购买任何商品")
user_choice=input("\033[31;1m是否重新购买商品(Y/y):\033[0m")
if user_choice == 'Y' or user_choice == 'y':
exit_flag = False
else:
exit_flag = True
else:
print ("商品编号有误,请输入整数类型编号")
# exit_flag = True